Visual Narrative Perception and Comprehension
We have developed a theoretical framework to explain how perception of scenes and events is connected to comprehending visual narratives (e.g., comics and movies). It is called the Scene Perception & Event Comprehension Theory (SPECT) . To find out more about it, see Loschky, Larson, Smith, & Magliano (2020), and Loschky, Hutson, Smith, Smith, & Magliano (2018).
Film Comprehension and Eye Movements
When watching a film, movie viewers typically aren't aware of how they make sense of the plot and understand the events that are occurring. Without realizing it, viewers must make connections and inferences from moment to moment and across different scenes and camera shots. To comprehend what a character is thinking or feeling, they must interpret their actions, body language, and facial expressions. A lot of unconscious effort goes into creating a mental model of an on-going film, but experience makes this task easier, since many people are introduced to television at a young age and grow up watching movies and learning to make sense of them. Research on comprehension of film narrative is a relatively new area in psychology. However, a handful of basic research studies in the field, along with decades of theory and practice in the film community, have laid the groundwork for asking the fundamental question: How do we understand movies?
Eye-movement research in film has recorded the phenomena of attentional synchrony, which occurs when multiple viewers look at the same things at the same time (Smith & Mital, 2013; Dorr et al., 2010; Hasson et al., 2008)(For an illustration of attentional synchrony by Tim Smith: https://www.youtube.com/watch?v=iDQlMrhyjtw). Attentional synchrony is thought to occur because of the physical movement of actors and objects in film (Mital et al., 2012), as well as elements specific to the film; most notably the editing used and how shots are framed (Cutting et al., 2011). In opposition to attentional synchrony across viewers, it would make sense that an individual film viewer would might guide their attention to areas of the scene that are of interest to them based on their individual comprehension of the narrative, which may differ from other people. For example, when you join your significant other on the couch to watch a movie, and join in the middle of the movie, though you are both watching the same movie, your understanding may be different from your significant other's, at least at the beginning. Will that difference in understanding also produce differences in what each of your look at? There is a large body of evidence that when people look at pictures, they guide their attention based on a task they have (Yarbus, 1967; DeAngelus & Pelz, 2009), and when they are reading (Rayner, 1998) they guide their attention based on their understanding of the text. However, comprehension guiding attention in film may be very different than the guidance of attention in looking at pictures and during reading. Most notably, the stimulus-driven qualities of film that create attentional synchrony across different viewers may make viewers less likely to guide their eye movements based on their comprehension.
Research Projects
Two projects in the visual cognition lab have tested the relationship between eye-movements and comprehension in narrative film (Loschky, Larson, Magliano, & Smith, 2015; Hutson, Smith, Magliano, & Loschky, 2017).
A video-recorded lecture at Kyoto University describes both of these studies.
The competing hypotheses tested in these experiments were:
Mental Model Hypothesis: Top-down processes (involved in comprehension) will guide viewer attention creating low attentional synchrony between viewers with different understandings of the narrative.
Tyranny of Film Hypothesis: Bottom-up features will guide attention and wash out any comprehension-based differences between viewers.
In both studies, the first step towards testing the hypotheses was to manipulate participants' comprehension of the film they were watching. This was done using the jumped-in-the-middle paradigm. This paradigm uses the common experience of coming into a movie after it has started, for example while watching TV, and having difficulty understanding a movie for the first few seconds or minutes. especially compared to someone who was watching the movie from the beginning. For the experiments presented below, there were two conditions: the Context condition where viewers watched the full film clip, and the No-context condition where viewers did not see the beginning of the film clip. In both studies there were a series of comprehension measures including making a predictive inference at the end of the clip, and eye-tracking was used to test whether differences in comprehension changed where participants looked.
In Study 1, a 6-shot movie clip from the James Bond film Moonraker (depicted below) was used (Loschky et al., 2015). The figure shows the character Jaws falling through the air and trying to open his parachute (Shot 1), realizing it will not deploy (Shots 2-3), and a couple of shots of a circus tent (Shots 4 and 6), with Jaws flapping his arms in an attempt to fly in between them (Shot 5). In the Context condition participants saw the 3 minutes leading up to the critical six shot sequence below, while in the No-context they saw only the six shot sequence.

In Study 2 (Hutson et al., 2017) a three minute continuous shot (i.e., without editing) from the opening scene of Orson Welles' Touch of Evil was used (depicted below). The clip starts with a close up of a bomb that is then placed in the car. After the bomb is placed in the car and the villain runs away, a couple who are unaware of the bomb get into the car and begin to drive down busy streets going in and out of the shot. Halfway through the clip a walking couple is introduced as new protagonists as the camera begins to follow them. Towards the end of the clip, the walking couple and the couple in the car reach a border checkpoint. After some time at the checkpoint, the walking couple passes through, with the clip ending as the walking couple are shown kissing in a close up. Two sets of experiments were run for the Touch of Evil clip. The No-context condition for Experiment Set 1 started just after the bomb is placed in the car, as the couple walked up to the car. In Set 2 the No-context group started watching the film while the walking couple was on the screen but the car was off-screen. Thus, in Set 1 knowledge of the bomb was manipulated, and in Set 2 knowledge of the bomb and the perceived protagonists (the couple in the car or the walking couple) were manipulated.

Overall, in both studies participants showed large differences in comprehension due to the jumped-in-the-middle paradigm and as measured in terms of their ability to make predictive inferences at the end of the clip. In the James Bond experiment participants in the Context condition were more likely to make the inference about the falling character landing in the tent. In the Touch of Evil experiment participants were more likely to make the inference that the bomb would explode. However, throughout most of the experiments conducted, these comprehension differences did not have an effect on eye-movements. It was only at specific times in each clip that small differences in eye-movements were found. This lack of an effect in the face of such large comprehension differences has been dubbed the tyranny of film (Loschky, Larson, Magliano, & Smith, 2015).
This research shows the power of attentional synchrony and how the tyranny of film can nearly eliminate individual differences in eye movements and attention that are due to differences in film understanding. However, some subtle variations in eye movements can still reveal differences between viewers depending on their understanding of a film. We are carrying out further research to understand the relationship between control of attention and the perception and comprehension of films.
Future work in this area will continue to test the role comprehension in guiding eye-movements in visual narratives using picture stories and other videos to extend our knowledge in this basic area of research testing the role of top-down processes in guiding visual attention. For a more applied emphasis, this work could also be extended to the realm of education where comprehension is a goal and videos and graphics are often used to aid comprehension.
If your interest is piqued, a more detailed account of this research can be found in the links at the bottom of this page to papers and conference presentations.
A video of a talk on Study 2 given at the 2015 European Conference on Eye Movements (ECEM) can be seen here.
Visual Narrative Comprehension: Drawing Bridging Inferences
How do we comprehend visual narratives, such as films, comics, picture stories, or other graphic narratives? One interesting piece of the puzzle concerns how we draw bridging inferences that fill in gaps in a visual narrative. For example, if you look at the images from a children's picture story below (from Mercer Mayer's book, "Frog, Where Are You?") you should have no problem in comprehending the events depicted in them. However, in one version it shows three images, showing a beginning-state, a bridging-event, and an end-state, while in the other version it shows only two of the images--with the bridging-event missing:
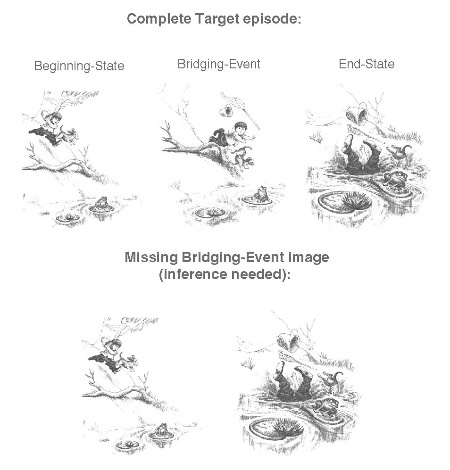
In the missing bridging event version, you have to make an inference, namely that the boy tripped. That helps to explain what happened in the end-state image, namely that the boy fell in the pond. This seems to be a very simple inference to make, and when viewing visual narratives we do this all the time without thinking about it. But research suggests that drawing such bridging inferences requires working memory. For example, if you didn't expect the boy to fall in the water after seeing him run down the hill in the previous image, then when you see him with his head in the water and feet in the air, you need to explain that to maintain a coherent understanding of the story. In order to explain that, you assumedly need to remember that in the previous image the boy was running down the hill (from short-term memory) and retrieve relevant information from long-term memory about how running down hills and falling are related--for example by tripping. These processes would assumedly occur in working memory. If so, then what sort of working memory is involved in generating such inferences while comprehending visual narratives? Is it visuospatial working memory (because the medium of the story is visual and spatial in nature) or verbal working memory (because it is a narrative, which, like language, involves sequentially ordered information), or a combination of both? In a recent study (Magliano, Larson, Higgs & Loschky, 2015), we investigated these questions. Our results suggest that both visuospatial and linguistic working memory are involved, but that sub-vocal processing (narrating the story verbally in your head) is not. For more details, see Magliano, Larson, Higgs and Loschky (2015 ).
We have also investigated how viewers' eye movements help them to generate bridging inferences while reading picture stories (Hutson, Magliano & Loschky, 2018). We found that when viewers need to make such bridging inferences, they look at the picture longer. Furthermore, using eye tracking, we found that the reason they look longer is because viewers make about 20% more fixations during that time. We hypothesized that this is because they are need more information to make the bridging inference. If so, we then asked whether those extra fixations are sent to parts of the picture that are particularly informative for making the inference. To answer that question, we had another group of viewers click on the areas of the target images that they thought would help someone make those bridging inferences. We found that viewers who needed to make a bridging inference were more likely to look at those areas identified as helping to make the bridging inferences. So, this suggests that when viewers read a picture story, their understanding of the story from moment to moment guides where they look.
Finally, all of these studies on visual narrative perception and comprehension were conducted to test hypotheses generated by the Scene Perception & Event Comprehension Theory (SPECT) . If you are interested in knowing about that theory, we have two papers describing it (Loschky, Larson, Smith, & Magliano, 2020; Loschky, Hutson, Smith, Smith, & Magliano, 2018).
Related Publications [Current or Former Students' Names in Italics]
Related Conference Presentations [Students Names in Italics]
Hutson, J., Smith, T., Magliano, J., & Loschky, L. (2016, July). What guides eye-movements in film? Differences in the effects of comprehension and task manipulations. Poster presented at The International Society for the Empirical Study of Literature (IGEL) biennial meeting, Chicago, IL.
Hutson, J., Smith, T., Magliano, J. P., Heidebrecht, G., Hinkel, T., Tang, J.-L., & Loschky, L.C. (2015, June). A general dissociation of eye movements and comprehension in Orson Welles’ “Touch of Evil”: The role of context and protagonist in narrative film viewing. Poster presented at the annual meeting of the Society for Cognitive Studies of the Moving Image, London, UK.
Loschky, L. C., Smith, T., Magliano, J. P., (2015, June). An integrative framework for visual narrative perception and comprehension. Talk presented at the annual meeting of the Society for Cognitive Studies of the Moving Image, London, UK.
Magliano, J. P., Larson, A. M., Higgs, K., & Loschky, L. C. (2015, May).Generating bridging inferences while viewing visual narratives. Poster presented at the Annual Meeting of the Vision Sciences Society, St. Pete Beach, FL.
Hutson, J., Smith, T., Magliano, J., & Loschky, L. C. (2014, Nov). What drives eye movements in narrative film viewing? The roles of the film stimulus versus higher-level comprehension. Poster presented at the 2014 Annual Meeting of the Psychonomic Society, Long Beach, CA.
Loschky, L. C., Hutson, J., Magliano, J. P., Larson, A. M., & Smith, T. (2014, June). Explaining the Film Comprehension/Attention Relationship with the Scene Perception and Event Comprehension Theory (SPECT). Talk presented at the annual meeting of the Society for Cognitive Studies of the Moving Image, Lancaster, PA.
Hutson, J., Smith, T., Magliano, J., & Loschky, L. C. (2014, June). The tyranny of film: Understanding the eye-movements/comprehension relationship in Orson Welles’ “Touch of Evil.” Poster presented at the annual meeting of the Society for Cognitive Studies of the Moving Image, Lancaster, PA.
Loschky, L.C., Larson, A.M., Magliano, J.P., & Smith, T.J. (2013, Nov.) What would Jaws do? Investigating the eye movements and movie comprehension relationship. Talk presented at the 2013 Annual Meeting of the Psychonomic Society, Toronto, Canada.