MS in Statistics - Data Science and Analytics Track
Beginning in Fall 2018, the Statistics department will offer a new Data Science and Analytics track for the MS degree. Data Science is the #1 career in 2018, according to Glassdoor.com, and this track is specifically designed to enable graduates to enter this rewarding and expanding profession.
This track, which can be completed in four semesters, emphasizes the computational and modeling skills necessary to accommodate complex, often massive, data systems while maintaining a sound basis in statistical methodology.
This degree will equip graduates with practical knowledge of statistical machine learning methods, optimization theory for data science, and cutting edge computational statistical modeling tools, as well as the theoretical basis for these methods. These skills are necessary to recognize the opportunities and evaluate the subtleties inherent in data-driven decision making in the context of complex and large-scale data.
To support the Data Science and Analytics track, several new courses have been added to the Statistics department’s offerings. These courses are required for the Data Science and Analytics track, but they can also be taken as standalone courses. More details about these courses can be found at http://www.k-state.edu/stats/academics/courses.html.
For additional information about the MS track in Data Science and Analytics, see http://www.k-state.edu/stats/academics/gradstudents/DegreeMS.html
Optimization for data science (STAT 760)
Provides students with the necessary foundations to fully appreciate modern statistical modeling, which has optimization as its foundation. The course incorporates theory and algorithms for linear and nonlinear optimization problems with continuous variables, including both constrained and unconstrained optimization for data science.
Discrete optimization and scalability for data science (STAT 761)
 Focuses on computationally efficient statistical methods that are essential for working with massive data sets. This course will give students a survey of modern tools for big data analysis and equip students with the background necessary to understand the computational complexities motivating these methods. These methods may be motivated with data ranging from stock market to elections to data extracted from search engines and social networks.
Focuses on computationally efficient statistical methods that are essential for working with massive data sets. This course will give students a survey of modern tools for big data analysis and equip students with the background necessary to understand the computational complexities motivating these methods. These methods may be motivated with data ranging from stock market to elections to data extracted from search engines and social networks.
Applied spatio-temporal statistics (STAT 764)
 Incorporates construction and analysis of spatial, time-series and spatio-temporal data sets. For context, focus will be on biological and ecological data, but these methods can be used in a variety of applications. Topics include data generation using geographic information systems (GIS), exploratory data analysis and visualization and descriptive and dynamic spatio-temporal statistical models.
Incorporates construction and analysis of spatial, time-series and spatio-temporal data sets. For context, focus will be on biological and ecological data, but these methods can be used in a variety of applications. Topics include data generation using geographic information systems (GIS), exploratory data analysis and visualization and descriptive and dynamic spatio-temporal statistical models.
Statistical machine learning (STAT 766)
 Addresses the complete process of building analytical tools suitable for learning from data. Topics include automatic online data collection, feature extraction, supervised and unsupervised statistical machine learning methods, and text processing/mining. Statistical methods such as regularized linear and logistic regression, classification trees, nearest neighbor methods, support vector machines and network analysis will be covered. Course work will include case studies and applications to business, government, social and news media data.
Addresses the complete process of building analytical tools suitable for learning from data. Topics include automatic online data collection, feature extraction, supervised and unsupervised statistical machine learning methods, and text processing/mining. Statistical methods such as regularized linear and logistic regression, classification trees, nearest neighbor methods, support vector machines and network analysis will be covered. Course work will include case studies and applications to business, government, social and news media data.
Applied Bayesian inference (STAT 768)
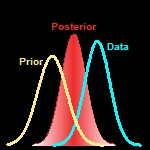 Provides an alternative to the traditional frequentist approach to statistical analysis. In a Bayesian approach, analysis of the data is driven by the analyst's prior information consistent with knowledge of the underlying science and data collection process. In addition to the basic principles of the Bayesian approach, this course will cover Markov Chain Monte Carlo (MCMC) methods, hierarchical models and model validation and selection. Computer-intensive applications will incorporate software such as R and WinBUGS.
Provides an alternative to the traditional frequentist approach to statistical analysis. In a Bayesian approach, analysis of the data is driven by the analyst's prior information consistent with knowledge of the underlying science and data collection process. In addition to the basic principles of the Bayesian approach, this course will cover Markov Chain Monte Carlo (MCMC) methods, hierarchical models and model validation and selection. Computer-intensive applications will incorporate software such as R and WinBUGS.